正本清源(二):从 prompt 到 harness,AI 使用者真正在解决的是什么问题
目录
当今世界,AI 正在以一种匪夷所思的速度发展,工具多的眼花缭乱,从 prompt 技巧到 RAG,从 agent 到 MCP,到如今的 harness,这些” 名词” 混乱到让人感到焦虑,每一波浪潮都在说自己是” 真正的答案”,上一波就被理所当然的贬为” 过时的东西”。
我认为,看懂这条时间线比学会任何一个工具都要重要。这篇文章想做的,是沿着时间线把每一波浪潮拆开:当时人们遇到了什么问题?根源是什么?解决它的过程中又出现了什么新问题?最后回到一个根本性的问题 —— 作为 AI 使用者,我们该如何在这片工具废土里找到适合自己的路?
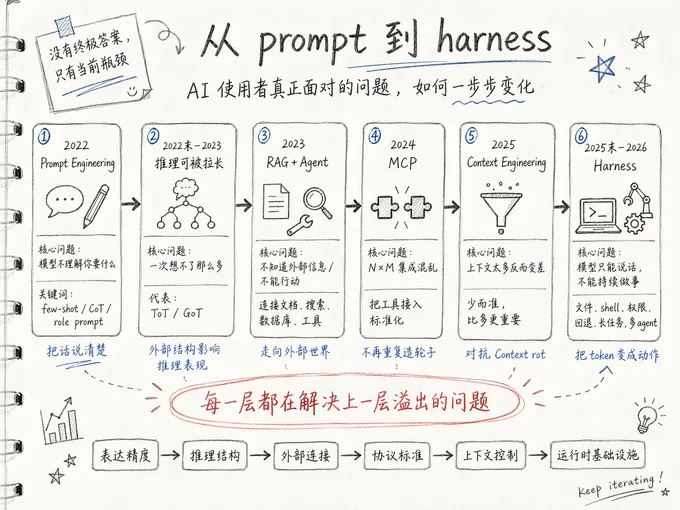
2022:Prompt Engineering 初露锋芒
2022 年 1 月,Google Brain 的 Wei 等人发表了 Chain-of-Thought,证明了一个在现在来看就是废话的问题:如果你让模型把推理步骤一步一步写出来,他在多步问题上的表现会显著提高。
几个月后 ChatGPT 问世,人们在接触的过程中意识到” 怎么跟模型说话” 也是一门学问。
今天回过头来看,prompt engineering 似乎有更深刻的意义,表面上来看,few-shot、chain-of-thought、role prompting 这些” 技巧集合” 有效。但是仔细想想你会发现,它们都是逼着使用者把一个模糊的问题变为模型能确切理解的指令,或者更直白来讲,它们通过结构化输出,把” 人没有把问题想清楚” 这个根本性问题绕过去。
这个阶段留下来了一个最核心的理念:
你的表达精度本身就是一种生产力,同时也决定了模型的能力上下限。
2022 年底到 2023:推理是可以被” 拉长” 的
Chain-of-Thought 证明了推理步骤的效果之后,有一个论点可以被轻松的引申出来:如果模型把逐步推理变为多步推理或者是树状搜索、图状搜索,会不会表现更好?
2023 年初,Yao 提出的 Tree-of-Thought 给出了肯定答案。他让模型在每一步都枚举多个可能的思路,然后用搜索算法遍历这棵思维树。
从表面上来看,这一阶段仍处于 prompt engineering 的影响下,但是他传递出来一个新的信号方向:
模型推理能力并不是一个静态的量,它会受到外部结构的设计影响,不同的设计会出现不同的效果。
现在的模型变聪明了,其实不准确 —— 在不断优化的结构下,模型能表现出的推理水平其实比它在单轮对话里面展现的要高得多。ToT 和 GoT 本身并没有直接成为今天主流 agent 架构的骨架(后者更多是 CoT 加工具调用的结合体),但是这个阶段留下来一条重要的认知,这条认知也在后面被反复验证,也是 harness 的雏形:
怎么围绕模型搭一个好的工作流程,常常比选什么模型更决定结果。
2023:RAG 和 agent,初探外部世界
到了 2023 年,人们开始遇到了 prompt 层面解决不了的问题:模型不知道你公司的文档,不知道今天的新闻,看不到数据库,也不能执行代码,你把 prompt 调到天上也没用。
这时候出现了两条路。一条是 RAG(Retrieval-Augmented Generation):模型在回答之前先去搜索相关文档,把结果放到上下文中。另一条是 agent + tool use:模型去调用外部工具,自主去搜索、执行、查询。
2023 年 Yao 的 ReAct 论文把这两条路缝合在一起:模型交替去思考和行动,先去推理下一步需要做什么,然后调用工具去获取信息,根据结果继续推理行动。同年 6 月份,OpenAI 推出了 function calling,他把 agent 能力下沉到了 API 层,LangChain 顺势成为了构建 agent 系统的标准框架。
这一个阶段问题很明确:模型的智能被它的” 信息封闭” 严重限制了。训练数据截止之后的事它不知道,你桌面上的文件它也看不到,生产环境的数据库它更连接不上。
但是又出现了新的问题:每接入一个工具都要写自定义集成,每个框架有自己的一套约定,不同模型供应商的 function calling 格式不一样,同一个能力在 LangChain 里是一种写法、在自研系统里又是另一种。工具越多,维护成本呈平方级增长。这个问题后来被 MCP 的正式命名为 N×M 集成问题 ——N 个模型、M 个工具,每一对组合都可能要写一遍。
2024:MCP 的必然
2024 年 11 月,Anthropic 发布了 Model Context Protocol(MCP),它们定义了一套协议,让工具提供方只实现一次 MCP 服务端,客户端只对接 MCP 规范,就能连上生态里任何遵循该协议的工具,他们将 agent 接入外部工具的方式标准化了。
MCP 在短短一年内,就已经扩展到了这一代 agent 的工具底座。到 2025 年末已经有超过 75 个连接器直接挂在 Claude 上,MCP 的 Python 和 TypeScript SDK 每月下载量合计超过 9700 万。
MCP 解决的问题不在” 怎么用 AI” 这一侧,而在” 怎么让 AI 的使用不重复造轮子”。
2025:Context engineering,上下文的讨论
到了 2025 年之后,一个反直觉的事实开始被人们认可:上下文窗口并不是越大越好。
早期人们认为,如果模型能看到 100 万 token,那就把所有可能相关的东西都塞进去,让模型自己挑所需要的内容。
但当 context 超过了某个阈值,模型从长上下文中准确召回信息的能力会下降,解决问题的能力反而会降低,这种现象被称之为”context rot”。
SWE-rebench 的维护者观察到模型性能在某个上下文长度附近会撞上一道硬墙,再往后不管上下文最多支持都会明显劣化。塞得越多,模型越走神,幻觉现象越严重。Databricks 的一项研究甚至在 32K token 附近就观测到了明显的精度下降。
这个现象引出了 context engineering 的概念。2025 年 9 月,Anthropic 在官方工程博客里把它称之为 prompt engineering 的自然延续,把焦点从” 如何写一条指令” 转到” 如何配置模型在每一步推理时能看到的信息”。同时期,Gartner 发布报告称 prompt engineering 正在被 context engineering 取代;Andrej Karpathy 和 Shopify 的 Tobi Lütke 也在社交媒体上公开支持这个转向。
模型的注意力是有限的。和人一样,给它看的东西越多,它能给每一部分的关注就越少。好的使用方式不是最大化信息输入,是精准地给它最少但最必要的信息。和 prompt engineering 时代的” 把话说清楚” 是同一条原理在不同尺度上的体现 —— 当年是一句话的精度,现在是整个上下文窗口的精度。
现在:Harness 是让模型能” 做事” 的基础设施
走到 2025 年底、2026 年初,我们来到了目前这个阶段 —— 称之为 harness 时代。Claude Code、Cursor、Codex 这些工具被统称为 harness,它们给一个只能” 说话” 的模型更多的” 手”,赋予它更大的” 权力”:文件系统访问、shell 执行、工具调用原语、权限和确认机制、错误回退、长任务的状态编排、多 agent 之间的协调通道、跨会话的记忆文件。
语言模型本身只能产出 token,harness 负责把这些 token 翻译成对真实世界的动作,再把真实世界的反馈翻译成模型能理解的输入。
harness 去解决的问题也是前几代自己产生的。现在的 agent 能力足够强、工具链足够完备、上下文管理足够讲究之后,单纯的” 模型 + 几个工具” 已经不够用,你需要一个能让模型在真实环境里持续工作的运行时。它自主要决定什么操作需要用户点头、什么可以静默执行;要在工具失败时选择重试还是回退;要把一个长任务拆分成子 agent 并回收它们的结果;要在会话中断后恢复到接近中断前的状态。这些需求合起来构成了 harness engineering。
但是 harness 层本身也在迅速制造新的问题。我自己配置过一整套 Claude Code 的定制化设施 —— 全局规则文件、领域规则文件、subagent、slash 命令、跨会话记忆 —— 每一个单独看都挺合理,但组合起来之后,系统的维护成本和认知负担开始吃掉它带来的收益。你花在记忆” 每个组件的状态、每个配置的影响范围、每次更新可能的连锁反应” 上的时间,开始和它节省的时间打平。
harness 是一把双刃剑:它让复杂协作成为可能,也让简单任务变得复杂。
贯穿所有阶段的模式
现在站在高处来俯瞰这条路径,你会发现一个清晰的循环结构:
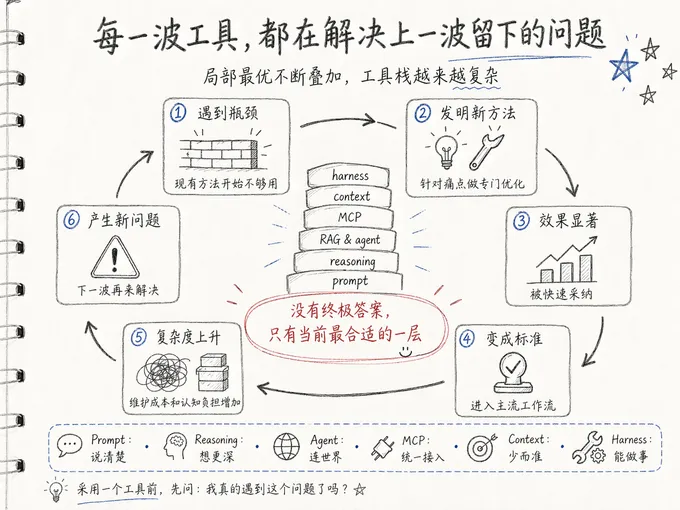
在使用过程中出现了某个瓶颈,然后有人去发明了一套新的方法去解决它,这套方法如果真的有效,就会被采纳变为行业标准。但同时会带来新的问题,等问题积累到一定程度,下一波人又会站出来发明下一套解决方案。
prompt 解决的是” 模型不理解你要什么”;推理链解决的是” 模型一次想不了那么多”;RAG 和 agent 解决的是” 模型不知道 / 做不了外部的事”;MCP 解决的是” 每个工具接入都要重写一遍”;context engineering 解决的是” 信息多了反而更糟”;harness 解决的是” 模型只能说话,不能在真实环境里做事”。
每一步都是合理的,每一步也都是局部最优。但连起来看,你会意识到没有任何一个阶段是” 终极答案”。每一层都在处理上一层的溢出。而那些宣称自己是终极答案的方案,无一例外地在下一两年内被发现有自己的天花板。
对普通使用者来说:如果你不理解一个新名词在解决什么问题,就不要急着采用它。采用一个为解决你还没遇到的问题而设计的工具,是在用复杂度换一个你用不上的能力。
该如何去做?
面对这条混乱不堪的路,合理的学习策略不是” 从下往上把每一层都学一遍”,也不是” 只学最新的那一层”。
我们需要确定自己在哪里。
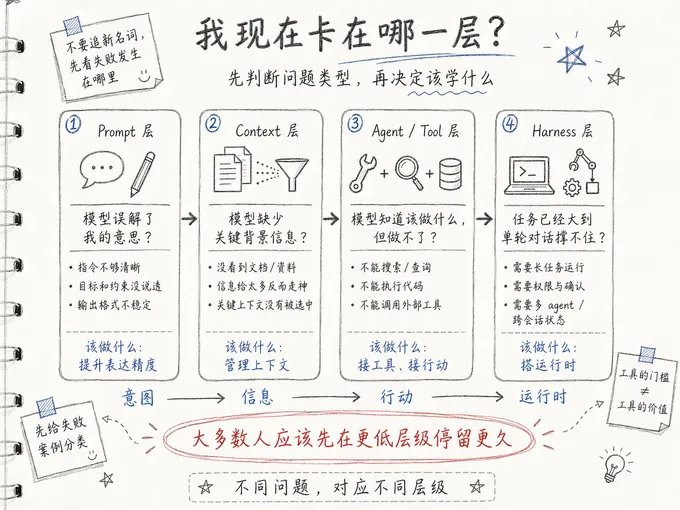
方法也不难,你观察自己最近几次和 AI 协作的失败案例,问一个问题:这一次失败,是因为模型误解了我的意图,还是因为模型缺少相关信息,还是因为模型无法调用某个工具或执行某个动作,还是因为任务规模大到单次对话已经撑不住,需要长时运行、权限控制、多个子 agent 分工、跨会话状态?这四个答案分别指向 prompt 层、context 层、agent /tool 层、harness 层。把失败案例分个类,你就知道自己该怎么做了。
其实我认为,大多数人应该在更低的层级上停留更久。
工具的门槛不等于它的价值。
很多人看到业界在谈 context engineering 就去学,认为这是” 更高级” 的东西。但 context engineering 只对那些已经建立了 agent pipeline、并且因为 token 预算在挣扎的人有意义。对一个日常用 AI 写邮件的人来说,context engineering 是过剩的复杂度。
每一次选工具的时候问自己两个问题:这件工具要解决的问题,我已经遇到了吗?如果没有它,我今天的工作会不会卡住?如果两个答案都是” 否”,这件工具就不是你现在该学的。它可能很好,但不是你的。
最后我想说的
从 prompt 到 harness 的演化,是一系列针对不同瓶颈的专门解决方案,不是一条从原始到高级的阶梯。它们共同构成了一个工具栈,每一层都在解决具体的问题。
作为使用者,你要做的不是追着每一层的新名词跑,而是搞清楚自己当前撞在哪一层的天花板上,然后精准地在那一层用力。看懂了这个演化逻辑,工具的” 混乱” 就不再混乱 —— 它只是一张地图,你需要的是知道自己站在哪里。